
أتمتة الاختبار (Test Automation) باستخدام Selenium
ما المقصود بأتمتة الاختبار؟
أتمتة الاختبار هي استخدام برنامج منفصل عن البرنامج الجاري اختباره للتحكم في تنفيذ الاختبارات ومقارنة النتائج الفعلية مع النتائج المتوقعة. يمكن استخدام أتمتة الاختبار من أجل أتمتة بعض المهام المتكررة ولكنها ضرورية في عملية اختبار البرنامج، أو إجراء اختبارات إضافية يصعب القيام بها يدويًا. زادت الحاجة إلى تطبيقات أتمتة الاختبار مع انتشار تطبيقات الذكاء الاصطناعي والتعلم الآلي (AI / ML) لتقديم إمكانية تحسين الاختبار، توليد الاختبارات الذكية، التنفيذ وإعداد التقارير.
فما المقصود بـ Selenium؟
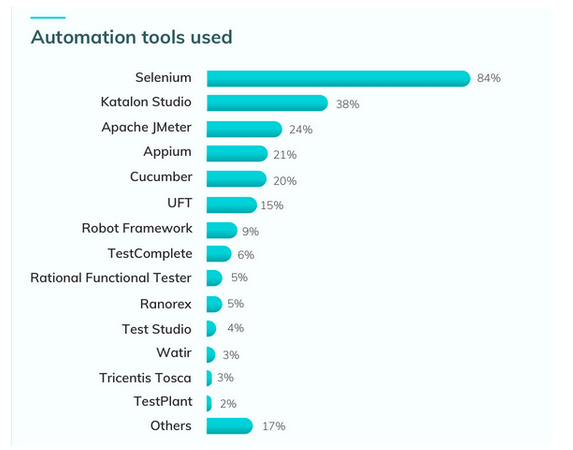
Selenium هي أداة مفتوحة المصدر تستخدم من أجل أتمتة تطبيقات الويب المختلفة، وهي تعتبر من أدوات الاختبار اﻷكثر استخداماً، وفقاً لهذه الإحصائية تقريباً 84% من المختبرين يستخدمون أو قاموا باستخدام Selenium في مشاريعهم.
من أين تأتي قوة Selenium؟
من النقاط التالية:
- أداة مفتوحة المصدر
- تدعم التصفح المتعدد Cross Browsing حيث يمكن استخدامها مع مختلف المتصفحات Chrome, Firefox, Safari…
- يمكن استخدامها مع أي نظام تشغيل Windows, Mac, Linux…
- يمكن استخدامها مع العديد من لغات البرمجة مثل C#, Python, Java, Rubby….
- تستخدم في عملية استخلاص المحتوى Web Content Scraping للحصول على معلومات تتولد بعد تفعيل كود JavaScript أو معلومات من الصفحات المحمية ضد استخلاص المحتوى.
جميع هذه النقاط جعلت Selenium أداة الاختبار اﻷكثر استخداماً.
مثال عن طريقة استخدام Selenium
بداية يجب أن يتم تحميل ما يسمى WebDriver والذي يستخدم من أجل بدء متصفح افتراضي ﻷداء عملية الاختبار، يمكنك تحميل ال WebDriver المتوافق مع المتصفح الذي تستخدمه من الرابط.
يجب أن يكون ال webdriver في نفس الـ path حيث يوجد كود الـ script أو يمكن تمريره كبارامتر للتابع الباني عن طريق التعليمة:
driver = webdriver.Firefox(executable_path="path_to_your_webdriver")
لتنصيب Selenium يتم استخدام الأمر:
pip install selenium
في المثال التالي سنستخدم geckodriver WebDriver المستخدم مع متصفح Firefox وسنقوم بكتابة الـ Script بلغة Python والمثال الذي سنستعرضه هو أتمتة عملية البحث في متصفح google واستخلاص العناوين في صفحة البحث الأولى.
import time from selenium import webdriver from selenium.webdriver.common.keys import Keys
بداية تم استدعاء كل من Keys, webdriver تمكننا مكتبة webdriver من استخدام الـ webdriver الذي قمنا بتحميله، أما Keys فهي تمكننا من استخدام لوحة المفاتيح كمستخدم طبيعي، مثل الضغط على زر Return.
driver = webdriver.Firefox()
الكائن driver يمثل المتصفح الافتراضي الذي سنتعامل معه، وهو من النوع:
<class 'selenium.webdriver.firefox.webdriver.WebDriver'>
من أجل الانتقال إلى الصفحة http://www.google.com نستخدم:
driver.get("http://www.google.com")
بعد أن تم الانتقال إلى الصفحة يمكن استخدام عدة طرق لتحديد عناصر الصفحة المختلفة، بعد أن نضغط بالزر اليميني على أي مكان فارغ في الصفحة واختيار Inspect تظهر لنا عناصر الصفحة كما في الصورة:
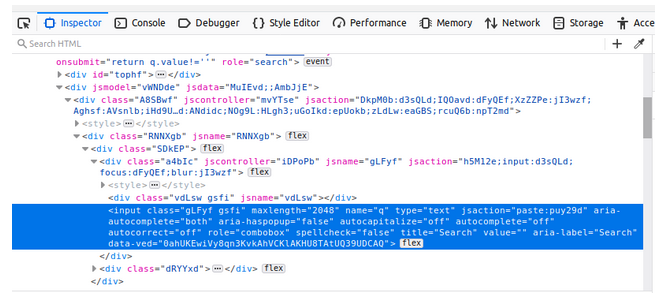
نجد أن نافذة البحث المراد تحديدها ( ملونة باﻷزرق ) تحتوي على مجموعة من الخواص التي يمكن استخدامها لتحديد العنصر، تدعم Selenium عدة طرق لتحديد العنصر مثل:
1. find_element_by_id() 2. find_element(s)_by_name() 3. find_element(s)_by_link_text() 4. find_element(s)_by_css_selector() 5. find_element(s)_by_class_name() 6. find_element(s)_by_class_xpath()
مثلا يمكن تحديد نافذة البحث عن طريق اسم العنصر، ويتم ذلك التعليمة:
search_field = driver.find_element_by_name('q')
بعد أن تم تحديد العنصر، يمكن استخدام التابع ()send_keys لكتابة النص المراد البحث عنه، ويتم ذلك باستخدام التعليمة:
search_field.send_keys('Automated Testing Using Selenium WebDriver')
من أجل إجراء البحث، يتم استخدام التعليمة التالية، والتي تحاكي الضغط على زر Return:
search_field.send_keys(Keys.RETURN)
يجب أن نقوم بانتظار صفحة الويب حتى تتحمل في المتصفح, من أجل ذلك يمكن استخدام التعليمة:
time.sleep(5) # sleep 5 seconds
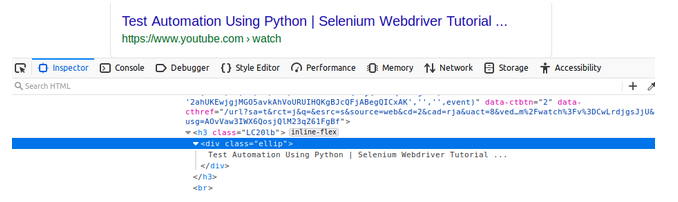
لتحديد نتائج البحث، نلاحظ أن جميع العناوين الرئيسية تتبع ل class = ellip لذلك يمكننا أن نستخدم:
lists = driver.find_elements_by_class_name("ellip")
لعرض النتائج:
print ("Found " + str(len(lists)) + " searches:")
for listitem in lists:
print(listitem.text)
ختاماً من أجل إغلاق المتصفح, نستخدم التعليمة:
driver.quit()
في المثال السابق تم استخدام كل من اسم العنصر واسم الـ class لتحديد العنصر، لكن من أكثر الطرق شيوعاً هي استخدام xpath في حال لم يكن للعنصر أي محدد آخر.
XPath هو اختصار ل XML Path وهو يعتبر تعبير أو لغة تستخدم للعثور على أي عنصر في صفحة الويب باستخدام تعبير مسار XML. يستخدم XPath أيضا للعثور على موقع أي عنصر على صفحة ويب باستخدام بنية HTML DOM.
يمكن استخدام أي إضافة للمتصفح للحصول على ال XPath للعناصر بسهولة, مثلا إضافة truepath لمتصفح FireFox عند الضغط بالزر اليميني على أي عنصر في الصفحة واختيار RelativeXPath يظهر مجموعة واسعة من الخيارات, مثلا من أجل نافذة البحث يمكن اختيار أحد الخيارات:
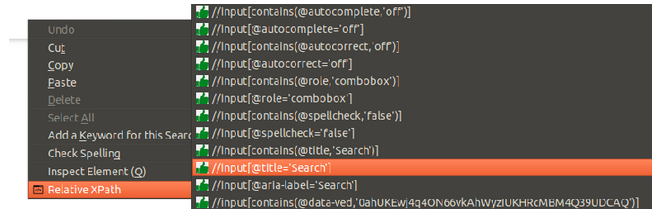
ويتم ذلك بالتعليمة:
search_field = driver.find_element_by_xpath("//input[@title='Search']")
استخدام Selenium في عملية استخلاص المحتوى ضمن المواقع المحمية ضد استخلاص المحتوى
بعض المواقع تعمد إلى الحماية ضد استخلاص المحتوى, من هذه الطرق Incapsula مثلا لو استخدمنا الطريقة المشروحة في المقال على هذا الموقع عن طريق ال requests او urllib سيكون الرد على الشكل:
<html style="height:100%">
<head>
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW"> <meta name="format-detection" content="telephone=no"><meta name="viewport" content="initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
</head>
<body style="margin:0px;height:100%">
<iframe src="/_Incapsula_Resource?CWUDNSAI=9&xinfo=5-21975557-0%200NNN%20RT%281523036235574%201%29%20q%280%20-1%20-1%20-1%29%20r%280%20-1%29%20B12%284%2c315%2c0%29%20U19&incident_id=543000770030160221-94045064965063893&edet=12&cinfo=04000000" frameborder=0 width="100%" height="100%" marginheight="0px" marginwidth="0px">
Request unsuccessful. Incapsula incident ID: 543000770030160221-94045064965063893
</iframe>
</body>
</html>
حيث أن الموقع سيميز أن الطلب ليس من متصفح بل Robot, لذلك لحل المشكلة يمكن أن يتم استخدام متصفح Selenium الافتراضي.
خاتمة
تم في هذه المقالة التعريف بشكل بسيط بأتمتة الاختبار باستخدام Selenium والخدمات التي تقدمها, يمكن الاطلاع على التوثيق الكامل ل Selenuim مع لغة python من خلال الرابط.