
ما هي عملية استخلاص المحتوى على الويب (Web Content Scraping)؟
هي تقنية تمكننا من جمع معلومات من صفحات الانترنت، معالجتها ومن ثم تخزينها في قاعدة بيانات أو إرسالها إلى إجرائية أخرى.
فبدلا من القيام بالنسخ و اللصق بشكل يدوي، نقوم بكتابة كود برمجي يقوم بطلب الصفحة ومعالجتها واستخراج المعلومات منها ومن ثم تخزينها .
إلى من موجهة هذه المقالة ؟
كل مطوّر ويب، او شخص يهتم بجمع البيانات بشكل مؤتمت من الانترنت
لنبدأ بمثال
لنفترض مثلا أننا نرغب بالحصول على كل دول العالم و أسماء عواصمها، ولدينا هذه الصفحة التي تحوي المعلومات المطلوبة.
طبعا يمكن أن نقوم بالأمر بشكل يدوي، ولكن سيكون ذلك مكلفا أكثر من ناحية الزمن وأقل كفاءة و أكثر عرضة للخطأ (وخاصة اذا كان عدد العناصر كبيرا جدا). أيضا تخيّل أن المحتوى يتغيّر بشكل يومي، عندها تحتاج إلى تخصيص جهد كبير من وقتك للقيام بالعملية.
سنقوم في هذا المقال بشرح آلية القيام بمهمة كهذه باستخدام البايثون خلال وقت قصير.
الخطوات الرئيسية للقيام بمهمة كهذه :
- تحميل الصفحة من الانترنت
- إعراب المحتوى (معالجة النص الموجود داخل الصفحة)
- ارسال ناتج الاعراب الى اجرائية أخرى (تخزينه في قاعدة بيانات أو في ملف نصي أو غيره).
تحميل الصفحة
يمكن أن يتم ذلك بطريقتين
1 باستخدام مكتبة requests أو urllib التي تسمح لنا بارسال طلبات HTTP و الحصول على الصفحة.
2 باستخدام مكتبات تعتمد على متصفحات الانترنت مثل selenium التي تقوم بالاتصال مع متصفح الانترنت المثبت مسبقا على النظام وتشغيله وطلب الرابط ومن ثم الحصول على الصفحة.
.تعتبر الطريقة الثانية أبطأ بكثير من الأولى، بسبب الوقت الضائع على تشغيل المتصفح و معالجته للنتيجة، لذلك نحن نختبر الطريقة الأولى دائما و لا نستخدم الثانية إلا عند الحاجة، مثلا للحصول على معلومات تتولد بعد تفعيل كود JavaScript.
سنستعرض تطبيق الطريقتين على الرابط السابق.
الطريقة الأولى باستخدام requests
import requests url = "http://www.bbc.com/arabic/learningenglish/2010/08/801016_cojo_arabic_guide5" result = requests.get(url) content = result.text
الطريقة الثانية باستخدام selenium
from selenium import webdriver url = "http://www.bbc.com/arabic/learningenglish/2010/08/801016_cojo_arabic_guide5" driver = webdriver.Chrome() driver.get(url) content = driver.page_source
إعراب المحتوى
هي عملية تحويل المحتوى الذي تم تحميله الى كائن برمجي (object) لنتمكن من معالجته، المكتبة الأقوى والأكثر شهرة لإعراب المحتوى هي BeautifulSoup.
قبل أن نبدأ بالمعالجة يجب أن نختار محددات للمحتوى الذي نريد استخراجه.
افتح رابط الصفحة في المتصفح واضغط بالزر اليميني على العنصر الذي يضم المحتوى بداخله، ثم اختار inspect كما هو مبين في الشكل
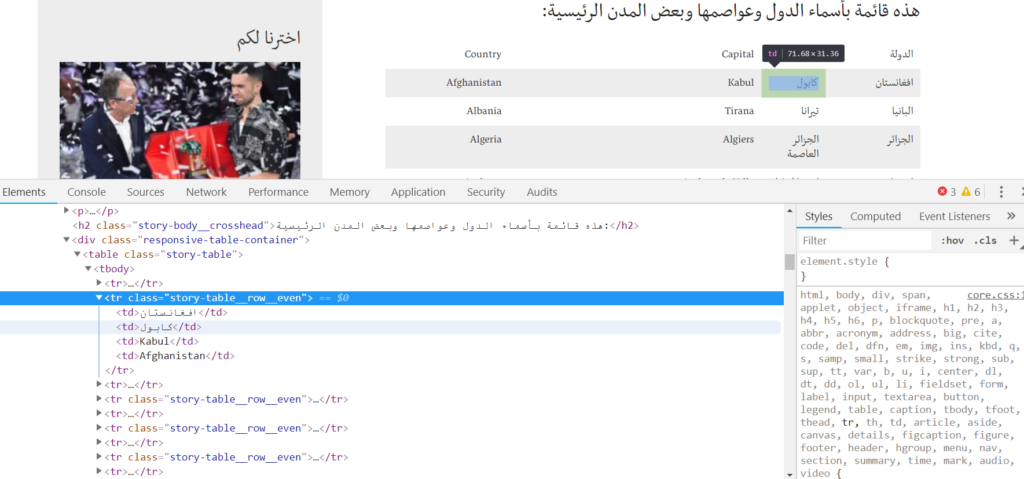
و بعد الضغط على inspect تظهر لنا نافذة تحوي عناصر الصفحة.
و نلاحظ أن المحتوى الذي نريده موجود داخل “table element”، وهذا العنصر ينتمي الى “class” هو “story-table”.
نحن بحاجة لهذه المعلومات كي نصل الى المحتوى المطلوب عند معالجة المحتوى.
و نلاحظ أن الجدول يحتوي مجموعة من العناصر هي عبارة عن أسطر <tr> و بداخل كل عنصر منها يوجد مجموعة من العناصر تعبر عن الاعمدة <td> .
لنبدأ بإعراب المحتوى :
from bs4 import BeautifulSoup soup = BeautifulSoup(content، 'html.parser')
في البداية نقوم بإرسال المحتوى الذي قمنا بتحميله الى الباني الخاص بالمكتبة، و نلاحظ أننا قمنا بتحديد اسم المعرب ‘html.parser’ في الباني أيضاً، و يمكن اختيار معرب آخر يسمى ب ‘lxml’ .
الكائن البرمجي الناتج “soup” يحوي نسخة معربة من المحتوى .
table= soup.find(“table”، class_=”story-table”)
باستخدام التابع find نقوم بتحديد اسم الوسم الذي نريد البحث عنه (في حالتنا “table”)، و نحدد واصفة أخرى تميز هذا الوسم و لتكن ال “class” الذي ينتمي له العنصر، يمكن اختيار واصفات أخرى إن وجدت كال “id” أو غيره، ستجد كل هذه المعلومات في المرجع الخاص بمكتبة Beautifulsoup .
الكائن البرمجي الذي يعيده التابع “find” من نفس نوع “soup” وهو يمثل جزء من النسخة المعربة السابقة.
rows= table.find_all(“tr”)
نقوم الأن بالبحث داخل الكائن “table” عن كل العناصر التي تحمل الوسم “tr”، باستخدام التابع “find_all” الذي يعيد مصفوفة من الكائنات البرمجية من نفس النوع السابق تمثل أسطر الجدول .
result = [] for row in rows[1:]: columns= row.find_all(“td”) country = columns[0].get_text() capital = columns[1].get_text() result.append((country، capital))
نعيد نفس العملية السابقة من أجل كل عنصر من عناصر المصفوفة حيث نستخدم التابع “find_all” لاستخلاص كل العناصر التي تحمل الوسم “td” التي تمثل الأعمدة في السطر.
و يكون أول عنصر في المصفوفة هو البلد (country) والعنصر الثاني هو العاصمة (capital).
و في كل مرة (من أجل كل سطر) نضيف الثنائية (country، capital) إلى المصفوفة النهائية.
ملاحظة : في ترويسة الحلقة بدأنا من العنصر الثاني (الذي ترتيبه 1) لأن العنصر الأول يحوي أسماء الأعمدة الخاصة بالجدول فقمنا بتجاهله.
إذا قمنا بطباعة المصفوفة النهائية نحصل على الخرج التالي :
('افغانستان'، 'كابول')
('البانيا'، 'تيرانا')
('الجزائر'، 'الجزائر العاصمة')
('اندورا'، 'اندورا لا فيلا')
('انجولا'، 'لواندا')
('انتيجوا وباربودا'، 'سان جونز')
('الارجنتين'، 'بوينس ايرس(ايريز)')
('ارمينيا'، 'يريفان')
('استراليا'، 'كانبرا')
('النمسا'، 'فيينا')
('اذربيجان'، 'باكو')
('جزر البهاما'، 'ناساو')
('البحرين'، 'المنامة')
('بنجلاديش'، 'دكـا')
('باربادوس'، 'بريدجتاون')
('بيلا روسيا'، 'مينسك')
('بلجيكا'، 'بروكسل')
('بيليز'، 'بلوم بان')
('بنين'، 'بورتو نوفو')
('بوتان'، 'ثيمفو')
…
يمكن تخزين هذه النتائج في قاعدة بيانات أو كتابتها في ملف أو غيره .
الخلاصة
قمنا في هذا المقال بشرح بسيط لمفاهيم أساسية في عملية استخلاص المحتوى من صفحات الويب، حيث رأينا كيف يمكننا استخلاص معلومات من صفحة انترنت بشكل بسيط و ببضع أسطر من الكود.
و لكن عندما نريد أن نحصل على معلومات كبيرة من عدة صفحات من موقع معين أو من عدة مواقع، يفضّل استخدام إطار عمل مثل scrapy الذي يمكننا من تحقيق ذلك بكفاءة.
و مهما كان إطار العمل المستخدم أو لغة البرمجة المستخدمة فجميعها تعتمد على الأفكار المطروحة في هذا المقال، الذي يمثل تعريفاً عملياً بالمفاهيم الأساسية في عملية استخلاص المحتوى.