
عمليه (التعرف على الكلام Speech Recognition) بدأت قبل عصر الديجيتال وتحديدا في عام 1952 من قبل IBMوكان النظام تماثلي Analogue. ولكن لم يكن قادرا الا للتعرف على الارقام من 0 الى 9. وبعدها بعشر سنوات كان بإمكانه التعرف على 16 كلمه انكليزيه.
وهذا يدل على صعوبه الوصول الى هذه القدره. وظلت المحاولات مستمره حتى الوصول الى 20000 كلمه حتى منتصف الثمانينات من القرن الماضي. وهكذا استمرت المحاولات حتى ظهور الذكاء الصناعي الذي ادى الى نقله نوعيه في هذه التقنية, و الان يمكن لبعض البرامج والتقنيات ان تتعرف غلى الاصوات البشريه وتمييزها عن باقي الاصوات بل تمييز صوت شخص معين عن صوت شخص اخر, كما تم التوصل الى تقنيه لتحويل الكلام الى نص.
وهنا يجب ان نميز بين تقنيتين:
تمييز او ادراك الصوت البشري VOICE RECOGNITION
وهو قدرة البرنامج على التعرف على شخص بناءً على بصمته الصوتية الفريدة voiceprint
.و يعمل عن طريق تسجيل الصوت البشري ومن ثم اجراء عملية تطابق مع بصمة الصوت المطلوبة. من أجل التعرف على مالك الصوت الاصلي.
SPEECH RECOGNITION تمييز الخطاب او التعرف على الكلام
هنا لا يهم من هو صاحب الصوت ولكن المهم هو تمييز الكلمات التي يسمعها البرنامج ومقارنتها بقاعده البيانات الموجوده فيه.
كيف يعمل نظام التعرف على الكلام
بشكل عام يقوم برنامج التعرف على الكلام بتقسيم الكلام إلى أجزاء يمكن تفسيرها وتحويلها إلى تنسيق رقمي وتحليل أجزاء المحتوى.
ثم يتخذ قرارات بناءً على البيانات السابقة وأنماط الكلام الشائعة ، مما يضع فرضيات حول ما يقوله المستخدم.و بعد تحديد ما قاله المستخدم على الأرجح ، يمكن للجهاز الذكي تقديم أفضل استجابة ممكنة.
ولكن الانظمه الحديثه تتعرف على أكثر من الكلام, مثلا تطبيق شازام Shazam الذي اشترته Apple عام 2018 ب (400 مليون دولار) قادر على التمييز بين الكلام والموسيقى و التعرف على الاغنيه او المسلسل او الفلم او حتى الاعلانات فقط عبر فتح مكرفون الجوال وسماع مقطع صغير.
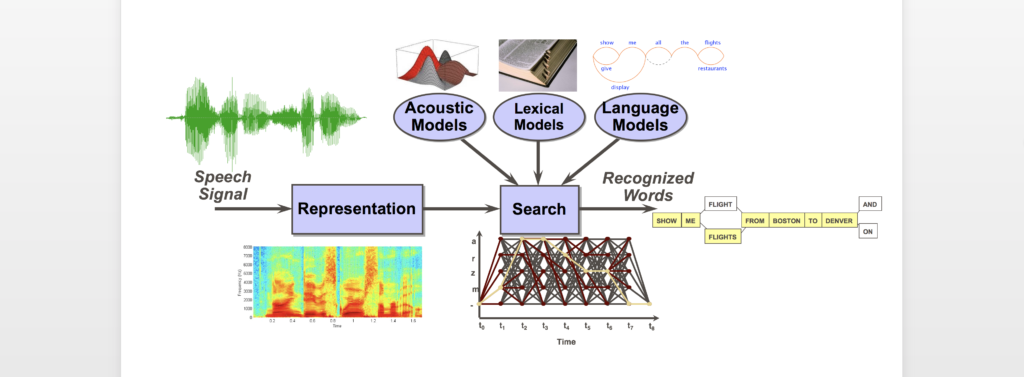
تعتمد أنظمه التعرف على الصوت Automatic Speech Recognition ASR, على ثلاثة عناصر
النمذجة الصوتية Acoustic modeling
وفيه يتم التفريق فيما بين الاشاره الصوتيه البشريه Voice signal
وبين الفونيمات Phonemes, (الفونيم هو أصغر وحده صوتيه تستعمل في بناء الكلام, بحيث لا يمكن استبدالها بفونيم اخر. مثلا في كلمتي (سار) و (صار) حرف السين مختلف عن حرف الصاد لذلك لديهما فونيمان مختلفان, وبالتالي اختلف معنى الكلمه بينما هاذان الحرفان لهما صوت واحد بالانكليزيه لذلك يعتبران فونيم واحد. والفونيم قد يختلف في صفاته بين لغه واخرى مثل حرفي P و B الذين لديهما جهر مختلف في الانكليزيه والفرنسيه بينما هما نفسهما بالعربيه) من أنواع هذه النمذجة يوجد Hidden Markov Mode HMM و يوجد انواع تستخدم الشبكات العصبية العميقة deep neural network
نموذج النطق The pronunciation model
والذي يحدد كيف يمكن جمع (الفونيمات) من اجل تكوين كلمة.
نمذجة اللغة Language modeling
و نظام يساعد على التمييز بين الكلمات الجمل التي تبدو متشابهة.
بعد تسجيل الكلام ، يتم مسح الضجيج وتصفية الإشارة, ثم يتم تقسيم التسجيل الى أجزاء صغيرة. ثم يتم تمرير كل جزء من خلال النموذج الصوتي.و تتم مقارنة هذه الأجزاء بالفونيمات، وهو نموذج إحصائي مبني منذ البدايه و يصف نطق كل صوت في الكلام. بناءً على هذه التطابقات، يتم جمع الكلمات من الفونومينات. تعتمد كفاءة العثور على الكلمات بشكل كبير على حجم قاعدة البيانات الصوتية المعدة مسبقًا.
تتوفر العديد من أنظمه التعرف على الكلام المفتوحه المصدر ومنها:
– نظام CMU Sphinx
ويحتوي نظام التعرف على الكلام المستمر continuous-speech recognition system
وتم تطوره في جامعه كارنيجي ميلون, ويمكن تحميله مجانا من موقع GitHub ويدعم العديد من لغات البرمجه.
– نظام HTK Toolkit والذي تم تطوره في جامعه كامبردج ويدعم لغات البرمجه c
وبايثون ولكنه ليس مفتوح المصدر بشكل كامل لكن في الموقع تتوفر كافه المعلومات عن كيفيه استخدامه.
– نظام Kaldi وهو مفتوح المصدر من اجل أنظمه التعرف على الكلام ومعالجه الاشاره, ومتوفر للتحميل من موقع GitHub ويدعم لغات C++ و Python.
تعمل تقنية التعرف على الكلام على زيادة إنتاجية المستخدم. إنه يلتقط الكلام البشري أسرع بكثير مما يمكننا كتابته. بالإضافة إلى ذلك ، يمكنك التحدث إلى جهازك عندما تكون يداك مشغولتين بعمل آخر ، وتقوم بعملين في نفس الوقت. إنه ضروري للأشخاص ذوي الإعاقة الذين لا يستطيعون استخدام أيديهم. كما إنها تضيف طبقة إضافية من الموثوقية من جانب الأمان لأنه ليس من السهل تزوير بصمة صوتية فريدة.
تم استخدام هذه التقنيه من قبل شركتي بدايه من قبل جوجل وابل عبر المساعد الافتراضي virtual assistant
ومن ثم تلتهما مايكروسوفت عندما اضافت نظام كورتانا Cortana و أمازون عبر Amazon Echo
مزايا التعرف على الكلام
- يزيد من إنتاجية الشركات
- أتمتة التفاعل بين الشركات والعملاء ؛
- يضيف مستوى أمان إضافي
- يلتقط الكلام أسرع مما يستطيع الإنسان كتابته.
- يساعد الأشخاص ذوي الإعاقة
- يساعد في التحكم في أجهزتك المنزلية
- يساعد السائقين في أنظمة ASR داخل السيارة
مساوئ أنظمه التعرف على الكلام
- لا تستطيع الأنظمة التعرف بشكل كامل على الكلام إذا كان المتحدث يتحدث بسرعة او بشكل غير واضح
- ضرورة توفير مفردات وفيره جدا من اجل تحسين دقة التعرف
- تتطلب كل لغة تدريبًا منفصلاً لـ ASR
- يمكن للشركات جمع واستخدام البيانات الصوتية للمستخدم دون إذنهم
- الوقت والتكاليف المالية باهظة
- يستهلك برنامج ASR قدرًا كبيرًا من الذاكرة ويتطلب قدرًا كبيرًا من ذاكرة الوصول العشوائي.
المراجع
https://www.csail.mit.edu/research/automatic-speech-recognition