
إن التعرّف على النصوص المكتوبة باللغة العربية يواجه مشاكل أكثر من نصوص اللغات الأخرى، سواء كانت النصوص مطبوعة أم مكتوبة يدوياً. يقدم هذا الفصل دراسة موجزة لبعض التحديات التي تواجه الباحثين في مجال التعرف على الأحرف العربية، واقتراح نظام جديد لإتمام عملية تحويل صورة النص العربي إلى ملف نصي وعرض المراحل المكونة له.
مشاكل التعرف على الأحرف العربية
1- مشاكل التعرّف على النصوص العربية المكتوبة يدوياً
تكتب غالبية الأحرف العربية بطريقة أقرب إلى الرسم منها إلى الأشكال الهندسية مثلاً ( كـ ، هـ ، س )، وبالتالي عند كتابتها يدوياً سوف تظهر أشكال كثيرة متعددة للحرف الواحد، يبيّن الشكل(2-1) نماذج مختلفة لأشكال كتابة الحروف ( س ، هـ ، ك ، ح ) يدوياً، حيث نلاحظ تغير شكل الحرف من طريقة كتابة إلى أخرى، مما يزيد صعوبة التعرف على الأحرف العربية المكتوبة يدوياً.
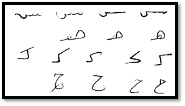
كذلك نلاحظ مثلاً في الشكل التالي شكل حرف الهاء الذي يمكن أن يشبه حرفين متصلين آخرين متصلين.

وبالتالي هناك صعوبة في التعرّف على هذه الأحرف وتمييزها عن التراكيب الأخرى، كذلك من الصعب أن نجد شخصين تتطابق أشكال خطوطهما بشكل كبير؛ وبالتالي فإن عملية تدريب الحاسوب للتعرّف على الكتابة اليدوية لا تزال في مراحل التطوير والبحث، ولم تصل إلى مراحل التطبيق الفعلي حتى في اللغات الأوربية إلى الآن، لذلك سنركز في هذا البحث على التعرف على الأحرف المطبوعة.
2- مشاكل التعرّف على النصوص العربية المطبوعة
عند التعرف على الكتابة المطبوعة يمكن تجاوز المشاكل الناتجة عن تنوع أشكال الحرف الواحد بتغير الشخص الذي يقوم بالكتابة، كذلك تشابه شكل الحرف مع تراكيب أخرى، ولكن يبقى هناك في التعرف على الكتابة المطبوعة مجموعة من المشاكل الموجودة أيضاً في التعرف على الكتابة اليدوية نذكر منها:
1- الاتصالية بين الأحرف:
تتميز اللغة العربية بوصلها للأحرف عند تشكيل الكلمة بعكس اللغات الغربية كالإنكليزية مثلاً التي تبقى أحرفها مستقلة (Isolated Character) إن هذا الوصل يستدعي استخدام خوارزميات تجزيء خاصة باللغة العربية قادرة على تحويل النص أو الكلمة إلى أحرف مستقلة، يبيّن الشكل التالي كلمة مكتوبة باللغة العربية وأماكن الوصل بين الأحرف

2- التنوّع في أشكال الحروف بتنوّع الخطوط العربية:
يوجد مجموعة كبيرة من الخطوط العربية والشكل التالي يبيّن مجموعة من نماذج مكتوبة بهذه الخطوط، حيث يلاحظ اختلاف شكل بعض الأحرف من خط إلى أخر.

هذا التنوع الكبير في أشكال الحرف الواحد من خط إلى آخر يصعّب من إمكانية التعرّف عليها.
3- التنوّع في شكل الحرف ضمن الخط الواحد:
يتغيّر شكل الحرف بحسب موقعه من الكلمة، فشكل الحرف في أول الكلمة مختلف عنه في وسطها كذلك في نهايتها، هذا يعطي عدداً كبيراً من الأشكال التي تستوجب التحليل والدراسة، يبيّن الشكل (2-5) مجموعة من الأحرف المكتوبة بالخط الروماني الحديثTimes New Roman والاختلاف في شكل الحرف بحسب موقعه من الكلمة.

4- تداخل الأحرف Overlap
إن تراكب الأحرف العربية في بعض الخطوط أحياناً بشكل عمودي أثناء الكتابة، يجعل تجزئة الكلمة إلى أحرف باستخدام خوارزميات بسيطة للتجزيء غير ممكن.
يوضح الشكل التالي عبارة مكتوبة بخط النسخ، وتوضح عملية التداخل بين حرفي الألف والكاف، وبين الكاف والباء، وبين اللام والحاء في كلمة الحمد.

5- اختلاف أبعاد الأحرف:
تتميز اللغة العربية بالاختلاف الكبير في أبعاد أحرفها سواء في العرض أو في الارتفاع، فمثلاً حرف الألف (ا) مرتفع لكنه غير عريض، بينما حرف الصاد مثلاً (ص) عريض وغـير مرتفع، وهناك أحرف عريضة ومرتفـعة مثل (ك ، ط ، ظ) وكذلك أحرف منخفضة وقصيرة مثل (و ، ة ، ر )، ويجب مراعاة هذه الاختلافات عند تطبيق خوارزميات التجزيء، ويعرض الشكل التالي عبارة مكتوبة باللغة العربية يظهر فيها التفاوت بين أبعاد الأحرف.

6- تأثير النقط والهمزات وعلامات التشكيل:
يوجد في اللغة العربية أحرف تحتاج إلى نقط مثل الفاء، والقاف، والغين، والباء وغيرها، هذه الأحرف مشابهة لأحرف أخرى ولا تختلف عنها إلا بعدد النقط أو بمكان توضع النقطة مثلاً (ج ، ح ،خ)، وكذلك (ب، ـيـ، ـنـ، ـتـ )، مما يجعل إشارات تشويش معينة ذات فعالية كبيرة في إحداث الخطأ مثلاً حرف الحاء المبين في الشكل التالي وبوجود التشويش يمكن تفسيره كحرف (خ) أو (ج ).

وستظهر نفس المشكلة بالنسبة لحرفي الألف والياء اللذين قد يترافقا بالهمزة (ء) (أ، إ ، ئ ، ـئـ )، ولا يمكن أن ننسى علامات التشكيل التي يمكن أن تظهر على الأحرف كالضمة (ُ )، والفتحة ( َ )، والكسرة (ِ )، والسكون ( ْ )، وعلامات التنوين ( الضم ٌ والفتح ً والجر ٍ ) والتي قد تسبب بعض المشاكل مثلا (حْ ) يمكن أن تقرأ (خ ).
نظم التعرّف على الأحرف العربية
إن الأبحاث المنشورة في مجال التعرّف على النصوص العربية قليلة إذا ما قورنت بغيرها من اللغات، والسبب الرئيسي لذلك هو التعقيد الذي تفرضه طبيعة الأحرف العربية المتصلة مع بعضها لتشكيل الكلمات، بالإضافة إلى مجموعة الأسباب التي سيأتي ذكرها بالتفصيل في الفصل الثاني.
شهد العقد الماضي تطوّراً كبيراً في مجال التعرّف على النصوص والكلمات والمخطوطات اليدوية، وأنجز العديد من تطبيقات التعرّف على الأحرف كالقراءة الآلية للعناوين البريدية والشيكات المصرفية، وقد اقتصرت بعض الدراسات على التعرّف على المصطلحات المستخدمة في العمليات المصرفية، لكن معظم الدراسات في هذا المجال تناولت اللغات الإنكليزية، والصينية، والفرنسية وحدث ارتفاع كبير في معدلات التعرّف على النصوص المكتوبة بهذه اللغات، في حين أن عدداً قليلاً من هذه الأبحاث تناول النصوص المكتوبة بالأحرف العربية علماً أن هذه الأحرف تستخدم في اللغة العربية، والفارسية، والأوردو، وهذه اللغات يستخدمها حوالي نصف مليار شخص في العالم، و يعود ذلك إلى عدم توفر الدعم الكافي من ناحية التمويل والوسائل المساعدة كقواعد البيانات النصية والمعاجم الرقمية وغيرها.
من الأسباب التي أدت إلى تأخر التعرّف على الأحرف العربية الاختلاف الكبير بين خصائص الكتابة العربية عن غيرها من الكتابات، إذ تتميز الكتابة العربية باتصالية الأحرف، وتنوع شكل الحرف حسب موقعه من الكلمة، وتنوع الخطوط، وبالتالي فإن العديد من التقنيات التي تم تطويرها للتعرّف على الأحرف المكتوبة باللغات الأخرى لا يمكن تطبيقها للتعرّف على الأحرف العربية، وفي جميع هذه الدراسات كان نظام التعرّف الضوئي على الأحرف العربية يتضمن المراحل التالية :
1 – تحويل النص إلى صورة رقمية باستخدام ماسح ضوئي.
2- المعالجة الأولية للصورة الرقمية من أجل تحسينها وإزالة آثار الضجيج.
3- التجزيء إلى أسطر، ثم إلى كلمات، ثم إلى أحرف.
4- استخلاص السمات.
5- التعرف على الأحرف باستخدام إحدى طرق التعرف.
وهذه المراحل متبعة في التعرّف غير المباشر off-line على الأحرف العربية .
دفع الاهتمام بالتعرّف على الأحرف العربية، إلى دراسة إمكانية ابتكار خطوط تسهل عملية التعرّف، وذلك بوضع فراغات صغيرة (غير مرئية تقريباً) بين الأحرف أثناء وصلها الأمر الذي يسهل عملية التجزيء إلى أحرف.
اقترحت الدراسات السابقة التي تمت في مجال التعرّف، على النصوص والكلمات والأحرف العربية، طرقاً مختلفة لاستخلاص السمات، والتعرّف على الأحرف مثل التعرّف الإحصائيStatistical Recognition ، والتعرّف القواعدي Syntactic Recognition [10]، واستخدام بعض الباحثين الطرق التركيبية البنيوية لاستخلاص السمات المميزة من النص مثل وجود ثقوب أو تقعرات أو نقاط، واستخدمت الشبكات العصبية الاصطناعية للتعرّف.
كذلك استخدمت تقنية تحويل هوف المعمم Generalized Hough Transform في استخلاص سمات الأحرف العربية المطبوعة لاستخدامه في التعرّف، حيث تتيح هذه التقنية إمكانية اكتشاف أشكال عشوائية ضمن صورة ما، وتتميز هذه التقنية بعدم تأثرها بالتشوهات الناتجة عن الضجيج، وقد أثبتت التجارب على هذه التقنية أنه من الممكن تعديلها للتعرّف على الأحرف حتى عند تغيير حجم الحرف أو كتابته بشكل مائل، الأمر الذي يمكن أن يحل مشاكل كبيرة عند التعرّف على المستندات العربية المطبوعة.
وقد قام Alexander Johnston باستخدام Zernike Moments لاستخلاص السمات، واستخدم الشبكات العصبية الاصطناعية للتعرّف على الأحرف الفارسية وحقق نسبة تعرّف 71%. كما تم استخدام الشبكات العصبونية الاصطناعية (Artificial Neural Networks) بنجاح في أنظمة التعرّف على الأحرف العربية بعد استخلاص السمات باستخدام التحليل الإحصائي ؛ وقد تم تدريب الشبكة العصبونية باستخدام خوارزمية مربعات المتوسط الأقل LMS، إذ تم تمثيل كل حرف عربي مطبوع بمصفوفة من الأرقام الثنائية التي استخدمت كمدخل لنظام استخلاص سمات بسيط خرجه يؤخذ إلى الشبكة العصبونية الاصطناعية، وقد بينت نتائج المحاكاة لهذا النظام أنه يعطي نسب تعرف عالية، ويقلل مربع متوسط الخطأ.
كذلك تم استخدام التحول المويجي ثنائي الأبعاد(2D Wavelet ) كمستخلص للسمات التي يتم تغذيتها إلى الشبكات العصبية الاصطناعية للتعرّف على الحروف اللاتينية المكتوبة يدوياً، الطريقة المقترحة هنا تم تقسمها إلى ثلاث خطوات أساسية:
الخطوة الأولى: هي المعالجة الأولية للصورة الأصلية حيث تحول إلى صورة رقمية باستخدام ماسح ضوئي بدقة ٣٠٠ نقطة في البوصة، ثم يتم استخلاص السمة باستخدام المويجات وفي النهاية استخدمت الشبكة العصبونية الاصطناعية متعددة الطبقات التي تم تدريبها باستخدام خوارزمية الانتشار الخلفي(Backpropagation) للتعرف على الحروف ؛ وعند اختبار كفاءة النظام بلغت نسبة التعرّف 89.2 %.
واستخدم كذلك chin code الذي يعتمد على ترميز الحرف وفقاً لاتجاه كتابته كسمة مستخلصة لكل حرف، ومن ثم استخدمت شبكة عصبية صناعية للتعرف.
استخدام بعض الباحثين نماذج ماركوف المخفية (Hidden Markov models HMM’s) كمصنف، ثم تم استخدام الشبكات العصبية الاصطناعية للتعرّف على الأحرف العربية المعزولة ولعدة أنواع من الخطوط كالكوفي، والديواني، والعربي الواضح بعد استخدام تحويل هـوف (Hough Transform) لاستخلاص سماتها، وكانت نسبة التعرّف الإجمالية97.36% .